
クラスター分析(階層/非階層)
クラスター分析は、「人(サンプル)」や「モノ(変数)」をグループ化する多変量解析法です。
客観的な基準によって、類似した傾向をもつ人(モノ)どうしができるだけ同じグループになるように、しかもグループ間はできるだけ離れるようにグループ分けを行います。
そして、それぞれのグループのボリュームや特徴を把握することで、商品・サービスのターゲット戦略の検討などに利用することができます。
Case Study 分析例
商品選択重視点によって消費者をグループ分けし、自社商品の戦略ターゲットを明確にしたい
クラスター分析は、同じ聞き方をした変数群を用いて、その変数群への回答傾向の類似性により、似たような人(モノ)をグループ化していきます。この事例では、選択重視点の変数群をもとにクラスター分析を行っています。その結果、消費者は5つのグループに分類されました。
なお、クラスター分析では、数多くの変数群をそのまま用いて分析するよりは、因子分析などでいったん要約し、要約された因子などを用いてクラスター分析を行うという手順で行われることが多いです(この事例も抽出した因子を用いた分析例です)。
同じ聞き方をした変数群を用いて、似たものどうしをグループ化する
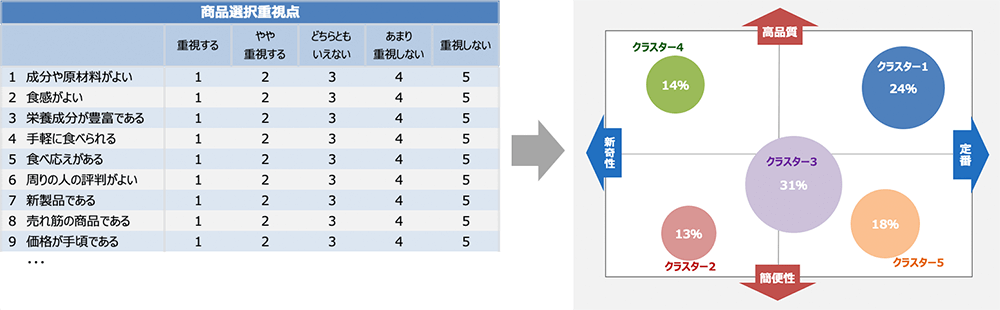
その5つのグループのボリュームとポジションを2次元空間にプロットしたのが右上の図です。
ここからは、各グループの特徴を細かく見ていきます。
各グループの選択重視点の特徴は?
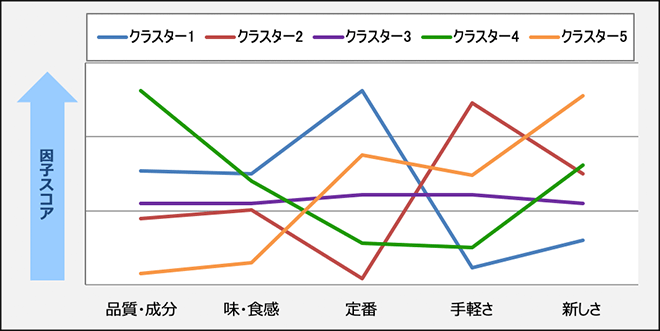
各グループの選択重視点の特徴を示しています。
上の図は、各クラスターの、選択重視点の変数群から抽出された因子への反応を比較しています。
この結果から、クラスター1は定番であることを重視する人たち、クラスター2は手軽さを重視する人たち、といった特徴がみてとれます。
さらに、各グループの他の設問への回答傾向を確認することで、それぞれのグループのデモグラフィック特性や意識・行動特性、自社商品の浸透状況などを把握し整理します。
各グループのプロファイルを整理する
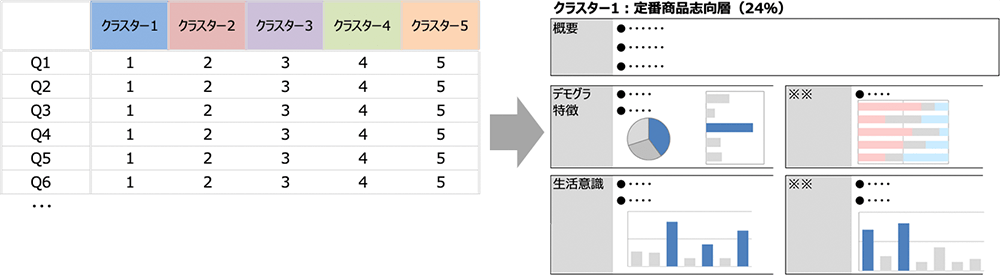
この結果を用いて、自社商品が今後狙うべきターゲットの特定およびターゲット攻略のための戦略立案に活用していきます。
<階層型クラスター分析と非階層型クラスター分析>
クラスター分析は、大きく分けて2種類の方法があります。ひとつは階層型クラスター分析、もうひとつは非階層型クラスター分析です。
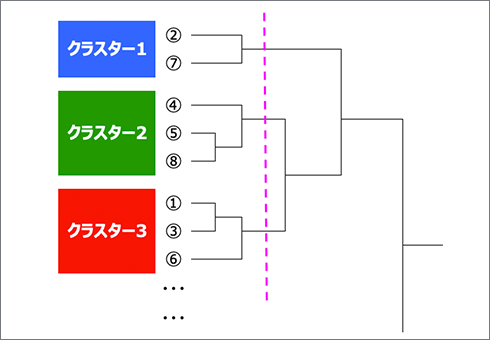
階層型クラスター分析のイメージ
非階層型クラスター分析
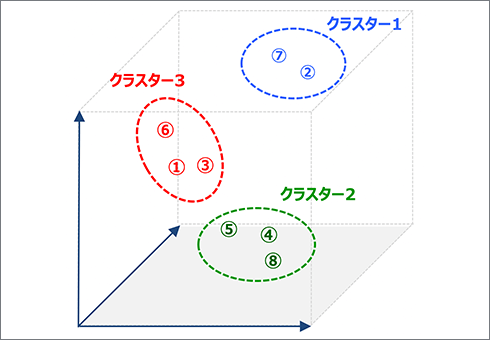
階層型クラスター分析は、もっとも距離が近いものを順次結合していくことでグループを形成させていく方法です。「人(ケース)」の分類のほか、「モノ(変数)」の分類に用いることができます。クラスターが結合していく過程を確認することによって、最適なクラスター数を決めていくことができます。ただし、クラスター間の距離が最大化している保証はないという難点もあります。
非階層型クラスター分析は、多次元空間内でできるだけ似た回答パターンのものが同じグループに属するように、かつグループ間は離れるように計算を繰り返していく方法です。この方法の場合、「人(ケース)」の分類に用いることはできますが「モノ(変数)の分類に用いることはできません。また、この方法の場合クラスター数を事前に決めておく必要があるため、最適なクラスター数自体を探索したい場合は不向きです。
両者の特徴をいかし、まずは階層型クラスター分析でクラスター数を決めて、そのクラスター数で非階層型クラスター分析を行う、といった2段階の方法を行う場合もあります。
POINT
上でも記したように、クラスター分析は、同じ聞き方をした変数群への回答傾向の類似性により人やモノをグループ化する手法です。そのため、クラスター分析を行う時は、どのような変数(質問項目)を準備しているかが極めて重要です。もしもそのカテゴリーや商品にとって重要な項目を聞き漏らしてしまっていたら、最悪の場合、有益なクラスター分析が出来なくなってしまうからです(これはクラスター分析に限らないことですが・・・)。
JMAは、お客様とのコミュニケーションを通じて分析の目的や課題を明確にしつつ、課題解決に向けて最適な調査設計~分析をご提案いたします。
コラム私の中の「それ以外」の部分
クラスター分析は、基本的には、個々の人・モノが所属するグループをただ1つに特定する分析法です。
しかし、私たちは、必ずしも「特定のグループの特徴」しか持っていないわけではないですよね?
うまい例えかどうかはあまり自信がないのですが、血液型がA型の私は、その性格も比較的A型的な特徴が強いとよく言われます。おそらく、性格についてのいくつかの質問に答えたデータを用いてクラスター分析を行うと、きっちりとA型グループに分類されるでしょう(厳密には、これはクラスター分析よりも判別分析のほうが向いているとは思いますが・・・)。
ですが、ですよ。私の中にもB型的な部分やO型的な部分があったりするわけです。「性格特徴データによるクラスター分析によって、あなたはめでたくA型グループに分類されました、パチパチ!」と言われても、生身の私は、「いやあ、そうなんだけど、私の中の大雑把なところとか、のんびり屋のところとか、「A型的ではない部分」ってのもあるじゃん、それってどう扱われるの?」という疑問は残るのです。そう、クラスター分析では、個々のケースが所属するグループは1つだけという前提で話を進めます。だけどその結果、個々のケースが持つ、所属するグループ的な特徴以外の部分、言い換えれば、他のグループに所属する可能性の部分(私のB型的な部分やO型的な部分)は捨象されることになります。
一方、昨今は「潜在クラス分析」という分析法にも関心が集まっているようです。「潜在クラス分析」は、個々のケースが複数のグループに所属していることを前提とした分析手法です。個々のケースがそれぞれのグループに所属する確率を算出することにより、従来のクラスター分析では顧みられなかった「それ以外のグループ」に所属する可能性にも光をあてるのです。その結果、個々の特徴や多面性を反映した分析結果を得られることにつながります。また、「潜在クラス分析」は、量的変数と質的変数を組み合わせて分析することができるため、量的変数しか用いることができないクラスター分析に比べて分析の汎用性が高いという特徴もあります。
ただ、潜在クラス分析はまだ事例が少ないこともあって、慎重な姿勢を取られる方も多いようです。今後徐々に使用ケースが増えるに従い、クラスター分析とどう使い分けるのかなどノウハウが溜まってくる、今後が楽しみな手法でもあります。
CONTACT
お悩みの整理や課題の発見から、
調査設計・分析、データの解釈、アイディア創出まで、
一貫したサポートを行います。
お問い合わせ
ください